🧬 FLUXMATERIA — LIFE SCIENCE
Binding affinity, off-target, microbiome,
from a SMILES and a target name
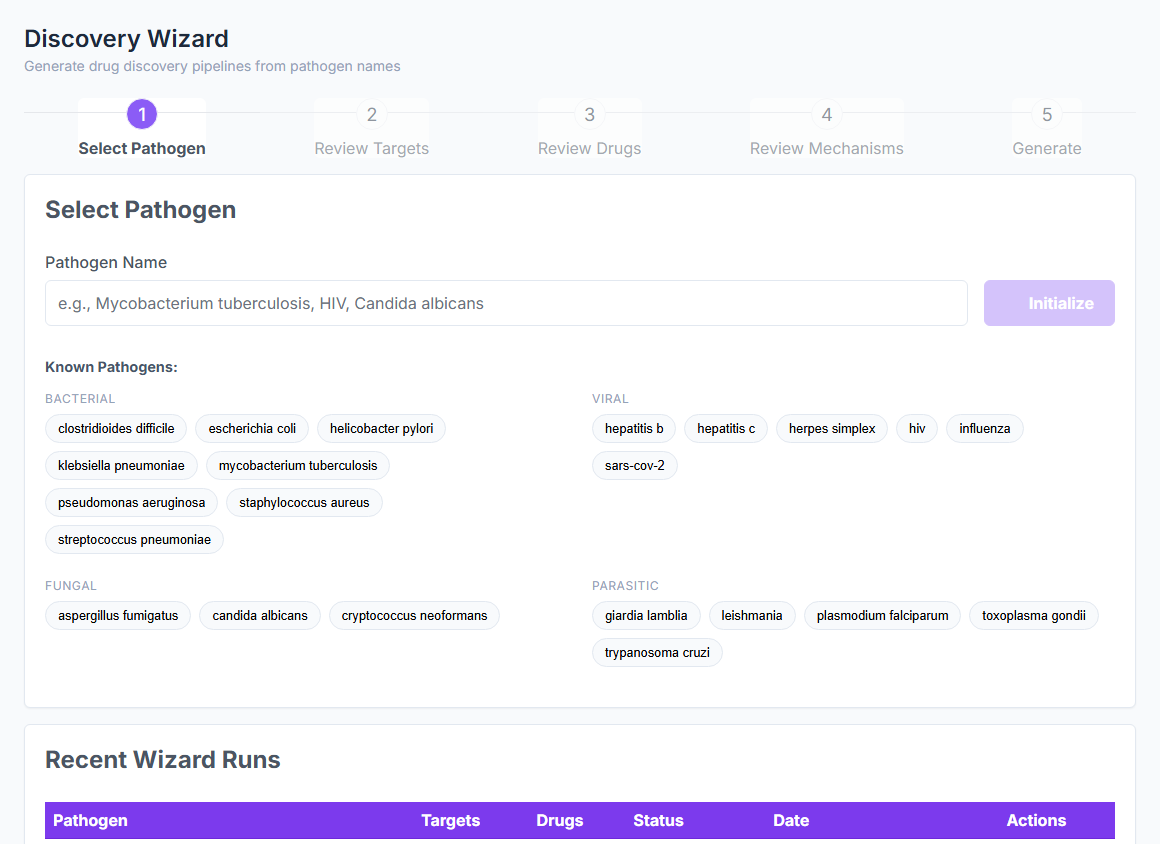
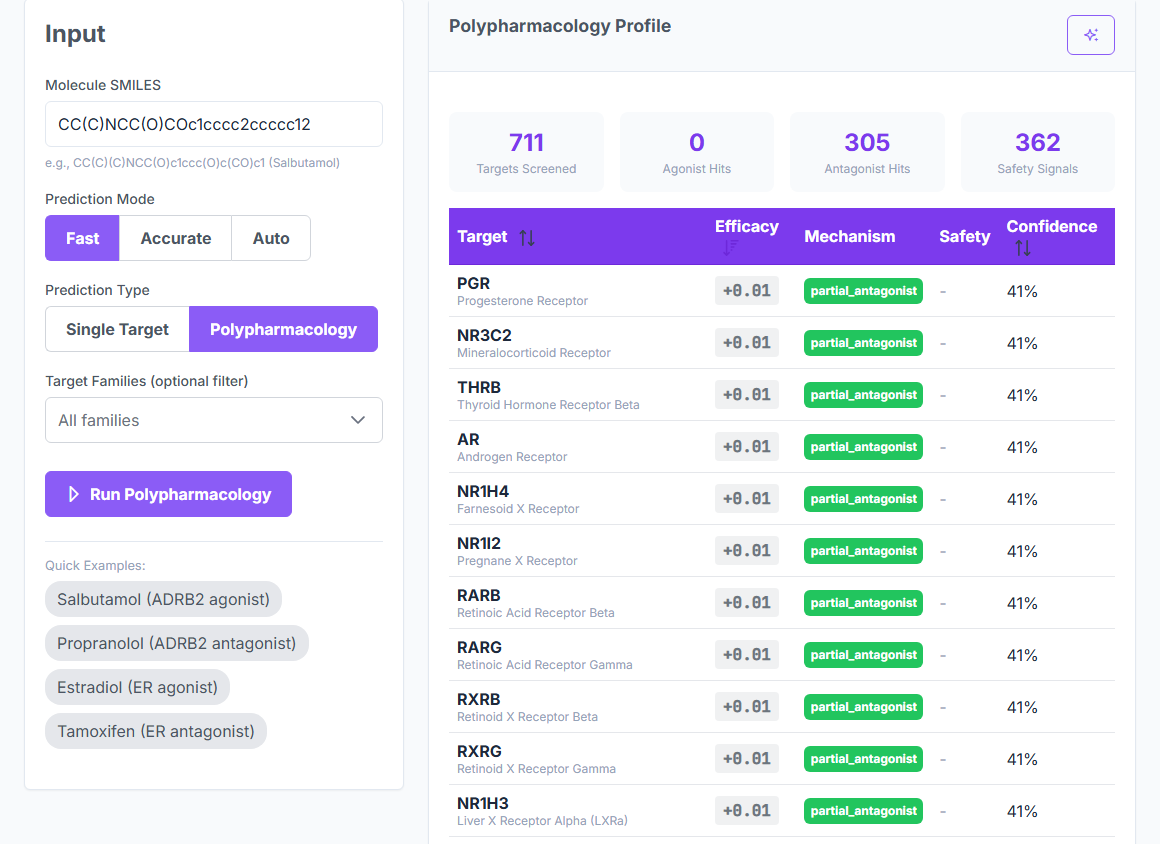
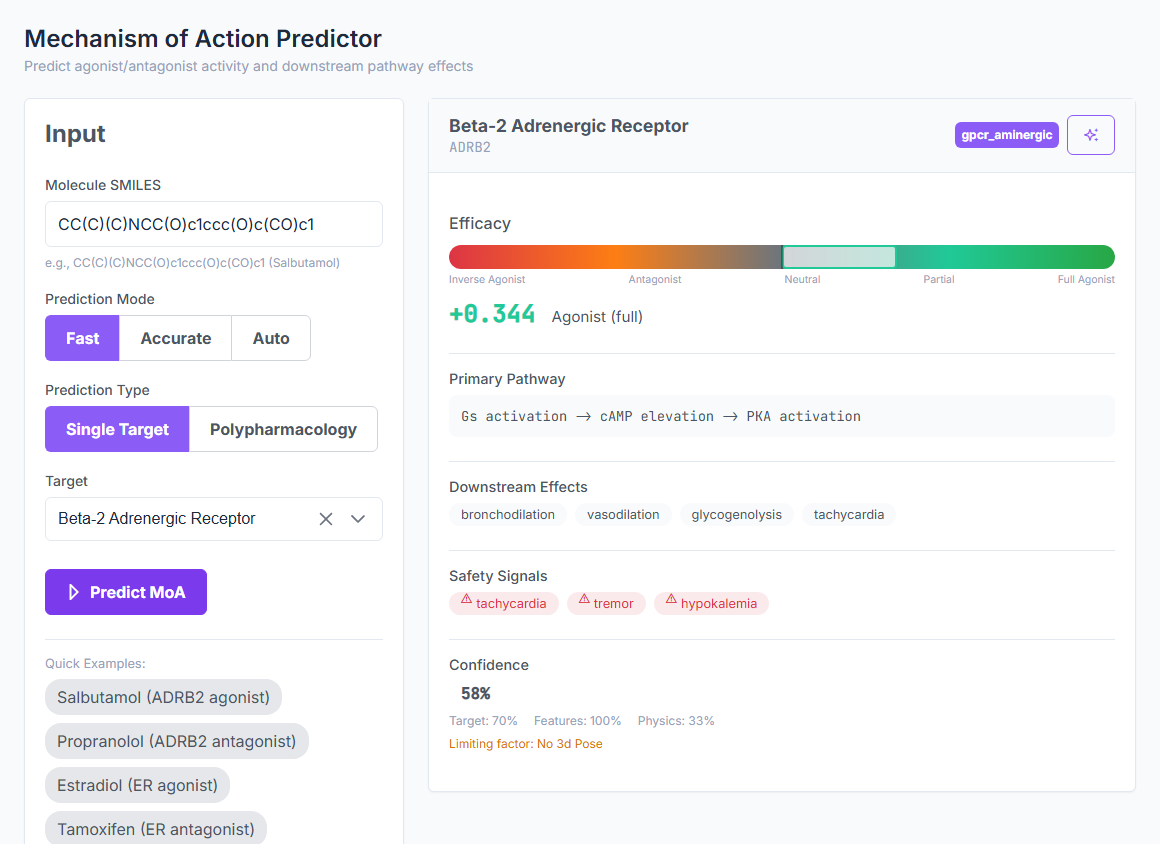
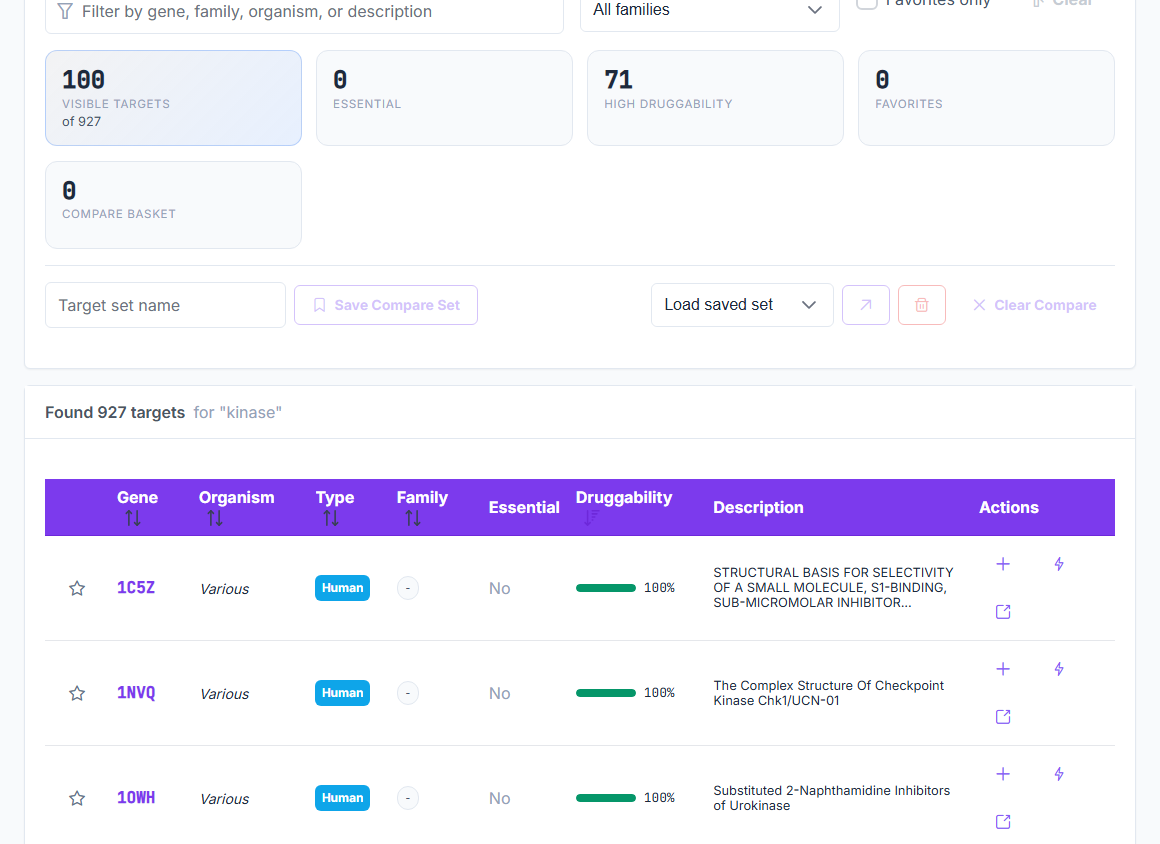
BioTarget scores pathogen efficacy, human off-target risk, and microbiome impact across 10,065 curated targets in 5 biological kingdoms. CASF-2016 validated. No crystal structure required. No training set. The whole multi-panel screen runs at 5,000+ predictions per second.
10,065 targets
CASF-2016 validated
Multi-panel selectivity
ADMET fusion
No ML
10,065
Curated targets across 5 biological kingdoms
r = 0.537
Pearson correlation on 270 CASF-2016 complexes
AUC 0.980
Target identification across the panel
5,000+ / s
Predictions per second — ~300,000× vs docking
0
Trained parameters · no crystal structure required